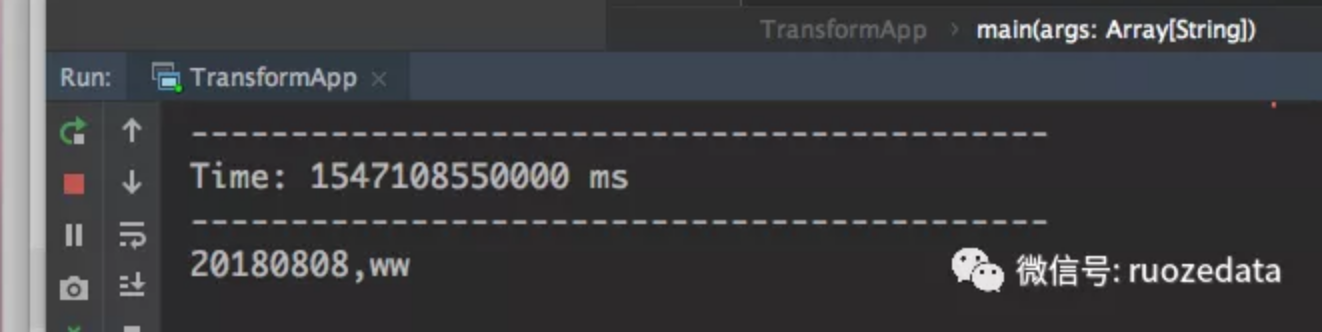
测试数据(通过Socket传入):
1 | 20180808,zs |
黑名单列表(生产存在表):
1 | zs |
思路
- 原始日志可以通过Streaming直接读取成一个DStream
名单通过RDD来模拟一份
逻辑实现
将DStream转成以下格式(黑名单只有名字)
(zs,(20180808,zs))(ls,(20180808,ls))(ww,( 20180808,ww))将黑名单转成
(zs, true)(ls, true)DStram与RDD进行LeftJoin(DStream能与RDD进行Join就是借用的transform算子)
具体代码实现及注释
1 | package com.soul.spark.Streaming |
最后输出: